
Preprocess tasks
This is a deprecated version of the SnowConvert documentation, please visit the official site HERE.
Description
These tasks are executed before the SnowConvert migration. This can be useful to improve the parsing process.
Split Task
This task splits the input code top-level objects into multiple files. The containing folders would be organized following the next hierarchy:
└───A new folder named ''[input_folder_name]_Processed''
└───Top-level object type
└───Schema nameExample
Input
├───in
│ DDL_Packages.sql
│ DDL_Procedures.sql
│ DDL_Tables.sqlOutput
Assume that the name of the files is the name of the top-level objects in the input files.
Inside the "schema name" folder, should be as many files as top-level objects in the input code. Also, it is possible to have copies of some files when multiple same-type top-level objects have the same name. In this case, the file names will be enumerated in ascending order.
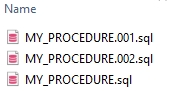
Requirements
In order to identify the top-level objects, they need a tag in a comment before the declaration.
The tag should follow the next format:
<sc-top_level_object_type>top_level_object_name</sc-top_level_object_type>
You can follow the next example:
Last updated