
DBC files explode
DBC files explode process steps
This is a deprecated version of the SnowConvert documentation, please visit the official site HERE.
Before migrating DataBricks workloads (.dbc files) you must run a explode process in order to extract the source code to migrate from the .dbc files and then run SnowConvert to migrate the extracted source code.
The explode process is done using a Python script, so Python must be installed on your machine. We recommend installing Python 3.7.
Run explode script
Run dbcexplode.py passing the .dbc file path as an argument
python dbcexplode.py <dbc_file_path>
The script will create a folder named <dbc_file_name>.dbc-exploded in the same directory where the dbcexplode.py script is placed.
This folder will contain a folder for each notebook found on the .dbc file. In the sample above, the .dbc file has one notebook (SanFranciscoFireCallsAnalysis (1).python)
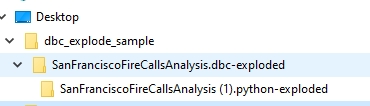
Inside this folder you will find one file for each command found on the processed notebook, the file name will be <notebook_name>-<secuence_number> where <secuence_number> is just the sequence number of the commands found on the notebook, in this example SanFranciscoFireCallsAnalysis (1)-001.md is the first command found on the notebook.
Note: When a notebook code cell contains a magic string, the script will create the file with .magic extension



Last updated